The Answering Machine
AI · Analytics · AWS Lambda · Builds · CSS · Data Visualization · Experimental · HTML · NLP · Python · Rapid Prototyping · React · Serverless · System Design
Check out the project on Github here: https://github.com/hockenmaier/voicequery
The Answering Machine is a proof-of-concept system that I built using pre-LLM natural language processing (NLP), specifically NLTK, to produce answers to questions asked about data in plain English.
Looking back, this project was a great insight into what LLMs immediately allowed that was incredibly difficult before. This project was several months of work that the openAI sdk would probably have allowed in a few weeks - and that few weeks would have been mostly frontend design and a bit of prompting.
Try it here: http://voicequery-dev.s3-website-us-west-2.amazonaws.com/ Github: https://github.com/hockenmaier/voicequery
The system uses natural language processing to produce answers to questions asked about data in plain English.
It is designed with simplicity in mind—upload any columnar dataset and start asking questions and getting answers. It uses advanced NLP algorithms to make assumptions about what data you’re asking about and lets you correct those assumptions for follow-up questions if they’re wrong.
It is built entirely out of serverless components, which means there is no cost to maintain or run it other than the traffic the system receives.
How-to
On a desktop or tablet, click the link in the header to navigate to the Answering Machine. For now, it isn’t optimized for smartphone-sized screens.
In order to use the Answering Machine, you can either select one of the existing datasets, such as “HR Activity Sample,” or upload one of your own using the homepage of the site:
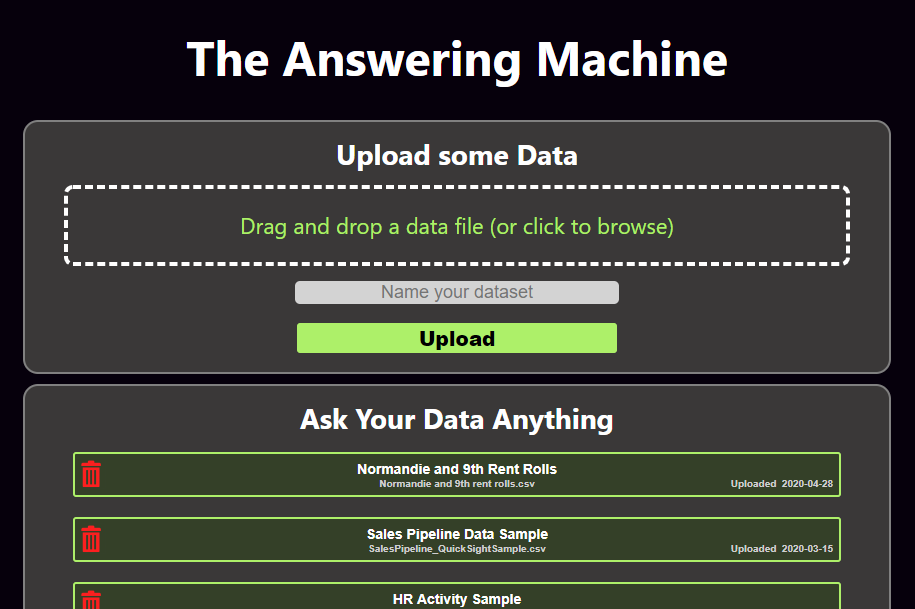
To upload your own, click in the upload area or just drag a file straight from your desktop. For now, use CSV data files. Excel and other spreadsheet programs can easily save data in the CSV format using the “File > Save As” or similar option in the menu. Each file needs a unique name.
When you hit the upload button, the site may not appear to change until the file is uploaded, at which point you’ll see it appear in the box labeled “Ask Your Data Anything” below. Click on your file to start using it with the Answering Machine, or click the red trash can icon to delete it.
There are no user accounts in this system yet, so the data you upload might be seen by other users using the system. Try not to use sensitive data for now.
Asking questions
When you enter a dataset, you’ll see a view that presents you with quite a bit of information:
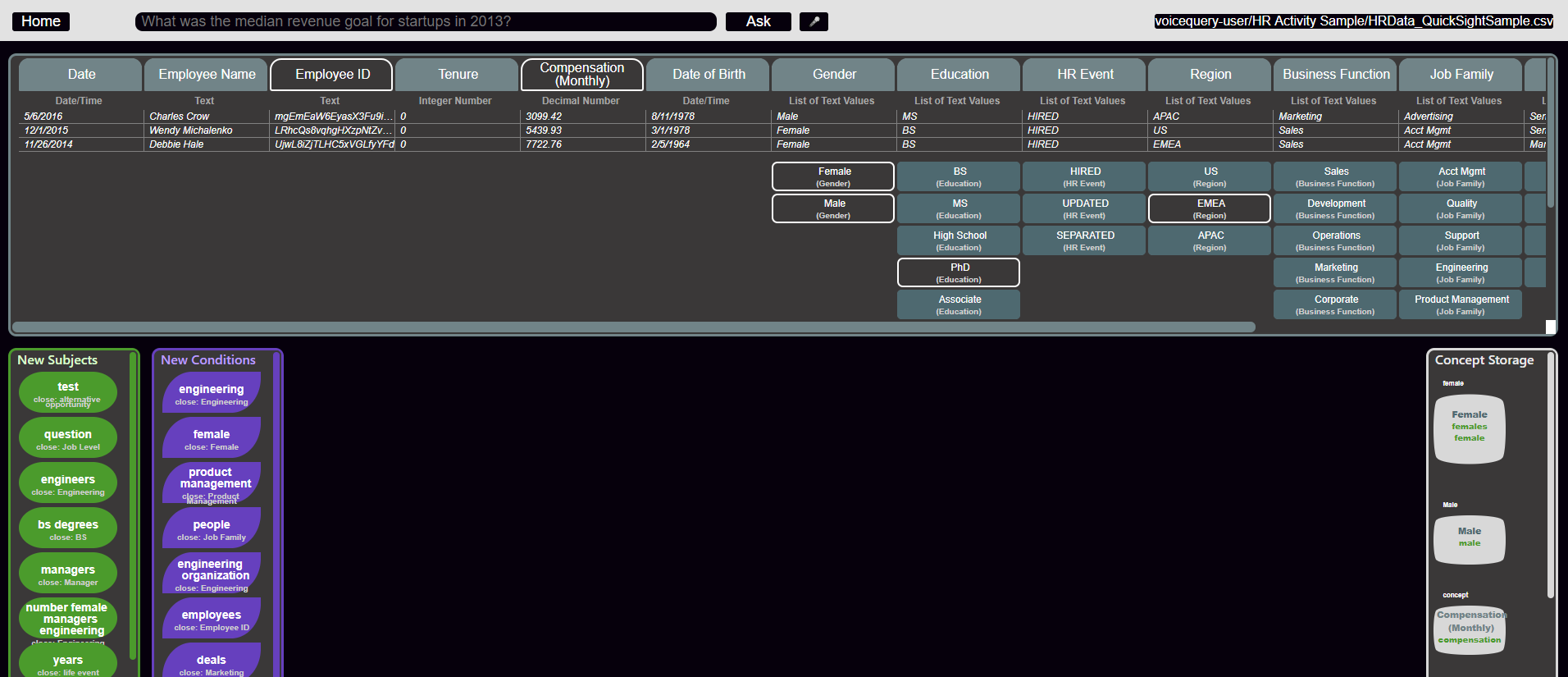
The only part you need to focus on right now is the information panel. This panel lists out all the fields (columns), data types of those fields, and some sample data from a few records in your dataset:
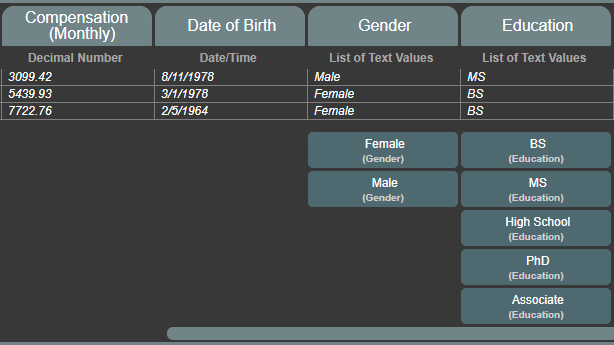
You can use this panel to start to formulate questions you might have about the data. If you see number values, you might ask about averages, maximums, or other math that might otherwise take some time to calculate. If you see a date, you can ask questions about the data in certain time periods.
Many datasets also contain fields that only have a few specific allowed values. When the Answering Machine sees fewer than 15 unique values in any field, the data type will be a “List” and it lists them right out under the sample values table. You can use this type of value to ask questions about records containing those specific values. For example, in the HR dataset, you might only be interested in data where the “Education” field’s value is “High School.”
Now look to the query bar to start asking your data questions:
The types of questions that will currently be automatically detected and answered are:
- Counts of records where certain conditions are true
- Math questions such as averages, medians, maximums, and minimums
These types of questions can be made specific by using qualifying statements with prepositional phrases like “in 2019” or adjective phrases like “male” or “entry-level.”
Combining these two ideas, you can ask specific questions with any number of qualifiers, such as:
“What was the median salary of male employees in the engineering department 5 years ago?”
Upon hitting the “Ask” button (or hitting Enter), the Answering Machine will do its best to answer your question and will show you all of its work in this format:
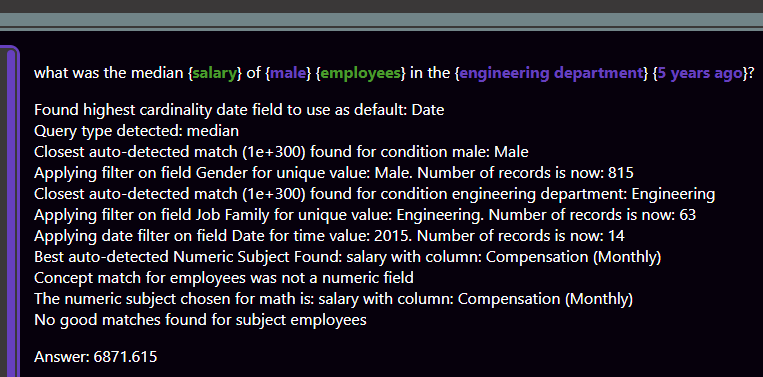
The last line in the response is the Answering Machine’s answer. In this case, it is telling you the metric you asked for with all your stipulations is 6871.6 dollars.
Moving up, you see a series of assessments that the Answering Machine has made in order to filter and identify the data you are asking about. Statements like “Best auto-detected Numeric Subject Found: salary with column: Compensation (Monthly)” provide a glimpse into one of the Answering Machine’s most advanced features, which uses a selection of NLP techniques to compare words and phrases that are similar in meaning, ultimately matching things you are asking about to fields and values that actually exist in your database.
At the very top of the response is how the Answering Machine’s nested grammar parsing logic actually parsed your question, with some specific pieces color-coded:
- Green chunks indicate “subjects” that were detected. Subjects are what the Answering Machine thinks you’re asking “about.” These should represent both the main subject and other supporting subjects in your question.
- Purple chunks are conditions. These are the things that the Answering Machine thinks you are trying to use to “specify” or filter data.
Now that your question is answered, you might notice that some new green and purple colored bubbles have appeared in the sections of your screen labeled “New Subjects” and “New Conditions.” We’ll call these “lexicon”:
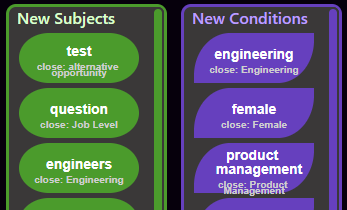
Forming Concepts
If the Answering Machine already understood what you were asking and successfully matched it to fields and values in your data, you don’t have to do anything with these. But often you will be using domain-specific lexicon, or the auto-matching algorithm simply won’t pick the correct value. These situations are what concepts are for.
To create a concept, click and drag on the green or purple “lexicon” bubble and move it out into the blank middle area of the screen. Then click and drag the field or field value from the info-panel at the top of the screen and drop it right on top of that bubble. You’ll see both the data bubble and the lexicon bubble included in a larger gray bubble, which represents the concept:
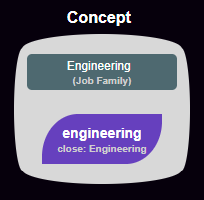
You can add more lexicon bubbles to this concept if they mean the same thing, but you can only use one data bubble.
Concepts override the Answering Machine’s auto-matching logic. If you ask another question containing a subject or condition that is now matched by a user to a data value, that data value will be used instead of the auto-match. If the concept isn’t working well, you can delete it by dragging all of the nested bubbles out of it either into the blank middle area or into the colored panel they originally came from.
Feel free to play around with new datasets and questions, and use the contact section of this site if you have comments or questions. When you ask questions or create/modify concepts, that data will automatically be saved to the server in real-time. You can close the page anytime and come back to your dataset to keep asking questions.
Remember that there are no user accounts, meaning you can share your dataset and work in tandem with others! But again, please do not upload sensitive data to this proof-of-concept tool as it will be available for other users to see and query.
Architecture
The Answering Machine is a purely “serverless” application, meaning that there is no server hosting the various components of the application until those components are needed by a user. This is true for the database, the file storage, the static website, the backend compute, and the API orchestration.
For the cloud nerds out there, here is a great article by Martin Fowler on what exactly “serverless” means, especially in terms of the backend compute portion, which is arguably the most valuable part of the application to be serverless. For reference, I am using Martin’s 2nd definition of “serverless” here.
This is a high-level map of all of the components that make the Answering Machine work in its current (June 2020) state. The API gateways, CloudWatch events, and some triggers “given for free” by AWS are left out of this for readability:
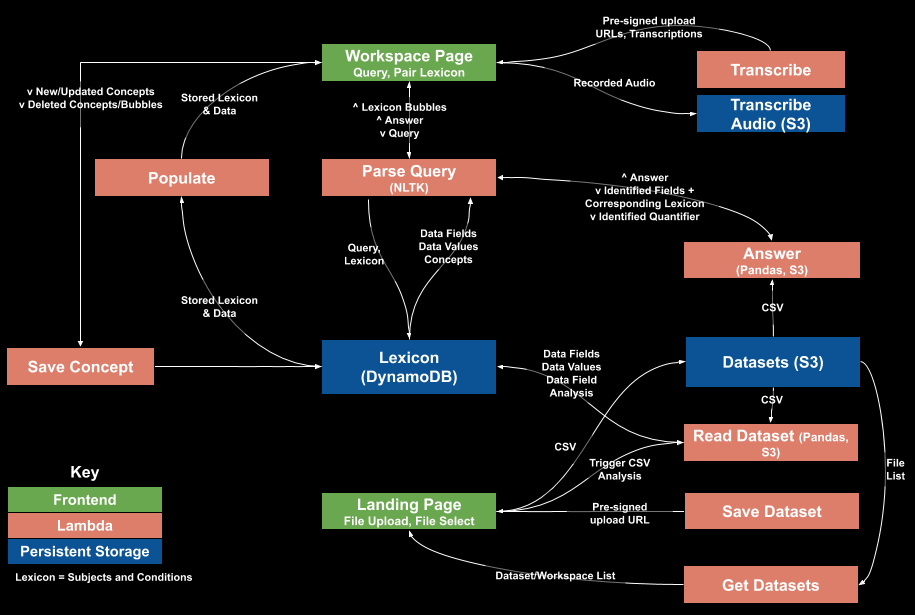
The full suite of lambdas and persistent storage services that make up the Answering Machine.



 200
200










